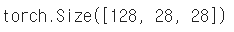과정 검토(2-4주차) PyTorch 데이터 세트 및 데이터 로더
모델에 데이터를 공급하는 방법
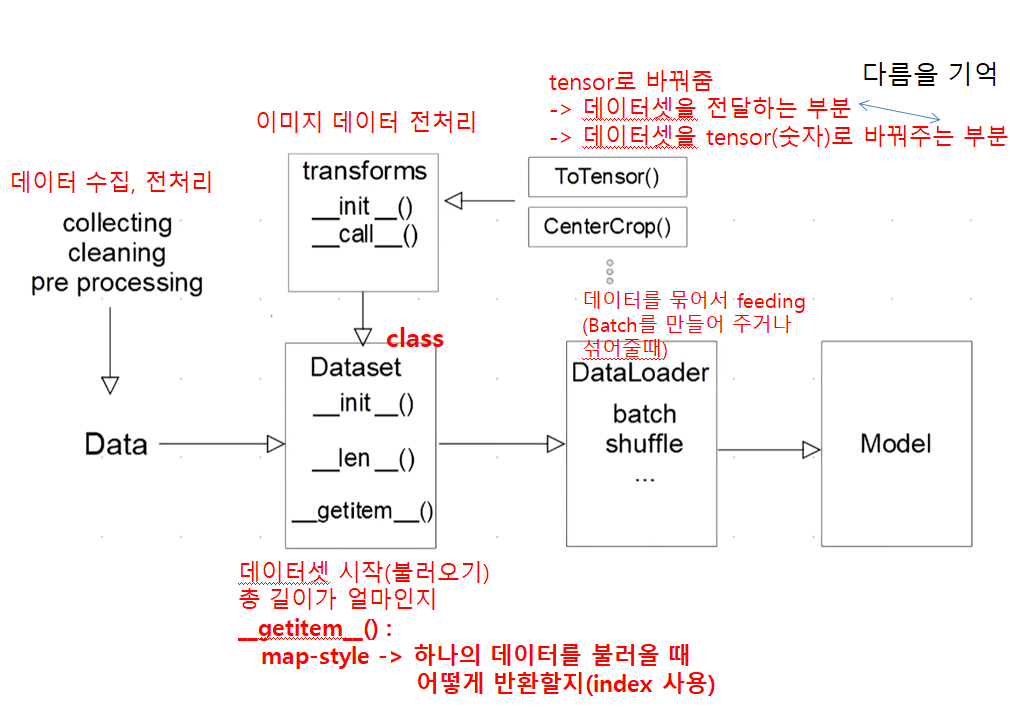
위의 순서를 알아야 합니다.왜냐하면
필요에 따라 Datasets, Transforms 및 DataLoader를 생성해야 하기 때문입니다.
데이터 세트 클래스
- 데이터 입력 유형을 정의하는 클래스
- 표준화된 데이터 입력 방법
- 이미지, 텍스트, 오디오 등의 측면에서 다른 입력을 정의합니다.
import torch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
## 초기 데이터 생성 방법을 지정
def __init__(self, text, labels):
self.labels = labels
self.data = text
## 데이터의 전체 길이
def __len__(self):
return len(self.labels)
## index 값을 주었을 때 반환되는 데이터의 형태 (X,y)
def __getitem__(self, idx):
label = self.labels(idx)
text = self.data(idx)
sample = {"Text": text, "Class": label}
return sample다음과 같은 코드를 작성하면
위의 CustomDataset을 입력합니다.
text = ('Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum')
labels = ('Positive', 'Positive', 'Negative', 'Negative', 'Negative')
MyDataset = CustomDataset(text, labels)
__getitem__은 DataLoader에 의해 호출됩니다.
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
데이터세트 클래스를 만들 때 주의하세요! ! -> 왜 사용하고 왜 태스크로 해야하는지..
- 각 함수는 데이터 유형에 따라 다르게 정의됩니다.
- 데이터 생성 시(__init__에서) 모든 것을 처리할 필요는 없습니다.
-> 학습에 필요한 시간에 따라 이미지의 텐서 변화 - Dataset에 대한 표준화된 처리 방법 제공 필요
-> 후속 연구원이나 동료에게 빛과 같은 존재 - 최근에는 HuggingFace와 같은 표준화된 라이브러리가 사용됩니다.
데이터 로더 클래스
- 데이터 일괄생성된 클래스
- 교육 전(GPU 피드 전) 데이터 변환 담당
- 텐서+배칭으로 변환하는 것이 주업무
- 병렬 데이터 전처리 코드를 고려해야 합니다.
데이터세트 생성
text = ('Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum')
labels = ('Positive', 'Positive', 'Negative', 'Negative', 'Negative')
MyDataset = CustomDataset(text, labels)데이터 로드 생성기
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))5개의 데이터가 있고 batch_size=2이므로 2 2 1로 나눕니다.

데이터 로더 클래스

DataLoader 클래스와 관련된 내용을 설명하는 좋은 블로그:
https://subinium.github.io/pytorch-dataloader/
예) 케이스 스터디
- 데이터 다운로드에서 로더로 직접 구현
- NotMNIST 데이터 챌린지 자동 다운로드
from torchvision.datasets import VisionDataset
from typing import Any, Callable, Dict, List, Optional, Tuple
import os
from tqdm import tqdm
import os
import sys
from pathlib import Path
import requests
from skimage import io, transform
import matplotlib.pyplot as pltimport tarfile
class NotMNIST(VisionDataset):
resource_url="http://yaroslavvb.com/upload/notMNIST/notMNIST_large.tar.gz"
##다운로드가 가능한지 설명
def __init__(
self,
root: str,
train: bool = True,
transform: Optional(Callable) = None,
target_transform: Optional(Callable) = None,
download: bool = False,
) -> None:
super(NotMNIST, self).__init__(root, transform=transform,
target_transform=target_transform)
if not self._check_exists():
self.download
if download:
self.download()
self.data, self.targets = self._load_data()
##데이터의 길이
def __len__(self):
return len(self.data)
## index를 받고 return해줌
def __getitem__(self, index):
image_name = self.data(index)
image = io.imread(image_name)
label = self.targets(index)
if self.transform:
image = self.transform(image)
return image, label
##해당 folder에서 file_list를 만들고 그 list에 대한 target 정의
def _load_data(self):
filepath = self.image_folder
data = ()
targets = ()
for target in os.listdir(filepath):
filenames = (os.path.abspath(
os.path.join(filepath, target, x)) for x in os.listdir(
os.path.join(filepath, target)))
targets.extend((target) * len(filenames))
data.extend(filenames)
return data, targets
@property
def raw_folder(self) -> str:
return os.path.join(self.root, self.__class__.__name__, 'raw')
@property
def image_folder(self) -> str:
return os.path.join(self.root, 'notMNIST_large')
def download(self) -> None:
os.makedirs(self.raw_folder, exist_ok=True)
fname = self.resource_url.split("/")(-1)
chunk_size = 1024
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" ##
filesize = int(requests.head(
self.resource_url,
headers={
"User-Agent" : user_agent
}).headers("Content-Length"))
with requests.get(self.resource_url, stream=True, headers={
"User-Agent" : user_agent
}) as r, open(
os.path.join(self.raw_folder, fname), "wb") as f, tqdm(
unit="B", # unit string to be displayed.
unit_scale=True, # let tqdm to determine the scale in kilo, mega..etc.
unit_divisor=1024, # is used when unit_scale is true
total=filesize, # the total iteration.
file=sys.stdout, # default goes to stderr, this is the display on console.
desc=fname # prefix to be displayed on progress bar.
) as progress:
for chunk in r.iter_content(chunk_size=chunk_size):
# download the file chunk by chunk
datasize = f.write(chunk)
# on each chunk update the progress bar.
progress.update(datasize)
self._extract_file(os.path.join(self.raw_folder, fname), target_path=self.root)
def _extract_file(self, fname, target_path) -> None:
if fname.endswith("tar.gz"):
tag = "r:gz"
elif fname.endswith("tar"):
tag = "r:"
tar = tarfile.open(fname, tag)
tar.extractall(path=target_path)
tar.close()
def _check_exists(self) -> bool:
return os.path.exists(self.raw_folder)
파일 다운로드
dataset = NotMNIST("data", download=True)
예제는 설명서를 확인하십시오!
fig = plt.figure()
for i in range(8):
sample = dataset(i)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
plt.imshow(sample(0))
if i == 3:
plt.show()
break

토치비전의 변신으로 데이터의 형태를 바꾸다
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose((
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
))
dataset = NotMNIST("data", download=False)DataLoader를 사용하여 데이터를 로드할 수 있습니다.
dataset_loader = torch.utils.data.DataLoader(dataset,
batch_size=128, shuffle=True)
가져온 데이터를 기능 및 레이블로 분리
train_features, train_labels = next(iter(dataset_loader))
분리된 데이터의 형태 확인
train_features.shape